
Die Nachfrage nach Künstlicher Intelligenz (KI) steigt kontinuierlich und damit auch der Bedarf an Rechen-Kapazitäten. KI-Anwendungen wie Deep Learning, Simulationen oder Prognosen benötigen enorm leistungsfähige Hardware, um aus komplexen Datensätzen valide Ergebnisse zu generieren. Server-Systeme mit NVIDIAs Grace Hopper TM Chip erfüllt diese Anforderungen heute und zukünftig perfekt: Der Superchip wurde speziell für das Training großer KI-Modelle, für generative KI, Recommender Systeme und Datenanalyse entwickelt.
Hier geht's zum Superchip-Wissen aus 1. Hand
AI Today - Ready for Take-off
Der Fortschritt der smarten KI-Technologien stieg in den vergangenen Jahren rasant: KI-Anwendungen wie Chat GPT, Simulationen in Bereichen wie der Medizin oder Recommender Systeme in Online-Shops lösen anspruchsvolle Aufgaben und erleichtern uns das tägliche Leben. Immer intelligentere Algorithmen und komplexere Datenanalysen vervielfältigen die Anwendungsmöglichkeiten. Der KI-getriebene Fortschritt benötigt aber Rechenleistung - und davon immer mehr. Systemarchitekturen wie NVIDIAs Grace Hopper TM liefern die nötige Power.
- Leistungsfähig: Grace Hoppers TM Kombination aus GPU, CPU und NVLink Interconnect bietet maximale Performance über viele Benchmarks.
- Vielseitig: Es gibt bereits viele Anwendungen, die auf Grace Hopper TM laufen, und es werden immer mehr.
- Energiesparend: NVIDIA Grace Hopper TM benötigt im Vergleich mit x86 Systemen weniger Energie.
Mit Best Practices zum Erfolg
Server-Systeme mit NVIDIA Grace Hopper
TM
Superchip:
Die erste Wahl für Ihre CEA-Workloads
-
Erfahren Sie mehr über die derzeit leistungsstärkste Architektur auf dem Markt, mit der Sie umfangreiche KI-Berechnungen und komplexe CAE-Simulationen in kürzester Zeit meistern.
- Introducing Grace Hopper:
Lernen Sie die leistungsstarke Architektur aus der NVIDIA Hopper GPU mit dem
Grace CPU (ARM Architecture) und dem schnellen NVLink Chip-2-Chip (C2C) kennen. - Optimized Performance:
NVIDIAs Grace Hopper TM liefert enorme Leistung, um umfangreiche CAE/CFD-Workloads
in kürzester Zeit zu bearbeiten. - Benchmark Insights:
Grace Hopper TM ist bei der CFD Software OpenFOAM besonders performant.
Erfahren Sie mehr Details anhand von ausgewählten Benchmarks. - Order Now and Starting with Computing Power for AI:
NVIDIA Grace Hopper TM Superchip ist ab sofort über GNS Systems erhältlich.
Ihre individuelle Beratung für
5 x höhere Leistung
Sie haben Fragen? Dann nehmen Sie Kontakt zu uns auf. Unsere Experten beraten Sie gerne rund um Grace Hopper TM und leistungsfähige Serversysteme zur effizienten KI-Nutzung.
Beste Performance für KI
Architecture Features
NVIDIAs Grace Hopper
TM
kombiniert die leistungsstarke Hopper GPU mit dem Grace CPU (ARM Architecture) und verbindet sie mit dem schnellen NVLink Chip-2-Chip (C2C).
Als erste NVIDIA-Datacenter-CPU für HPC und AI Workloads verwendet die
NVIDIA Grace CPU
72 Arm Neoverse V2 CPU-Kerne, um die maximale pro-Thread-Leistung aus dem System herauszuholen. Bis zu 480 GB LPDDR5X-Speicher bieten die optimale Balance zwischen Speicherkapazität, Energieeffizienz und Leistung.
NVIDIA Hopper
ist die neunte Generation der NVIDIA-Datacenter-GPU und ist speziell auf groß angelegte KI- und HPC-Anwendungen ausgelegt. Die verwendeten Thread Block Clusters und Thread Block Reconfiguration verbessern die räumliche und zeitliche Datenlokalität und halten die verwendeten Einheiten ausgelastet.
NVIDIA NVLink-C2C
ist NVIDIAs speicherkohärenter und latenzarmer Verbindungsstandard für Superchips. Es bildet das Herzstück des Grace Hopper
TM
Superchips und liefert eine Gesamtbandbreite von bis zu 900 GB/s.
|
Processor
|
Processor Family: NVIDIA Grace Hopper TM Superchip Processor Type: NVIDIA Grace TM 72 Arm® Neoverse V2 cores Max. TDP Support: 1000W Number of Processors: (1) Processors Internal Interconnect: NVIDIA® NV-Link®-C2C 900GB/s |
|
Form Factor
|
2U Rackmount |
| Dimensions | W x H x D (inch): 17.24" x 3.44" x 35.43" W x H x D (inch): 438 x 87.5 x 900mm |
|
Storage
|
Default Configuration: (4) E1.S NVMe SSD
|
|
Memory
|
Capacity: Up to 480GB LPDDRX embedded 96GB HBM3 GPU memory
|
|
Expansion Slot
|
Default Configuration: (3) PCle 5.0 x16 FHFL Dual Width slots
|
|
Front I/O
|
Power / ID / Reset Button Power / ID / Status LEDs (2) USB 3.0 ports (1) VGA port |
|
Storage Controller
|
Broadcom HBA 9500 Series Storage Adaptor Broadcom MegaRAID 9560 Series |
| Power Supply |
1+1 High efficiency hot-plug 2000W PSU, 80 Plus Titanium |
Ob Deep Learning, NLP (Natural Language Processing) oder Datenanalyse –
NVIDIAs Grace Hopper
TM
liefert enorme Leistung, um umfangreiche KI-Berechnungen und Simulationen
komplexer Zusammenhänge in kürzester Zeit zu ermöglichen.
High Speed
für Ihre Innovationen
Grace Hopper
TM
für
OpenFOAM
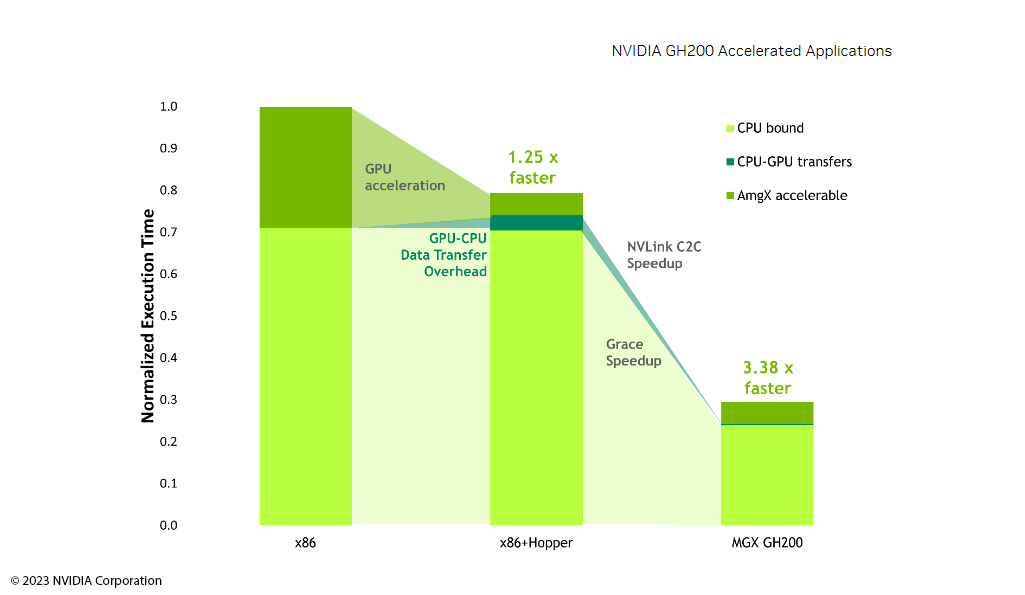
Mit dem NVIDIA Grace Hopper TM steht Entwicklern ein modulares System zur Verfügung, das selbst anspruchsvolle CFD-Simulationen mit OpenFOAM optimal unterstützt. Für die Anwendung komplexer Simulationsmodelle in der Produktentwicklung ist es notwendig, die Berechnungen massiv parallel auf modernsten Rechenarchitekturen durchzuführen.
OpenFOAM-basierte Anwendungen auf Grace Hopper TM -Architekturen nutzen das Leistungspotenzial der Server optimal aus. Im Vergleich zu anderen Systemen wie zum Beispiel dem x86 System ohne Hopper braucht die NVIDIA Grace Hopper TM -Architektur nur 15 Prozent statt 35 Prozent Runtime. Insgesamt werden in der Regel nur 85 Prozent des Runtimes CPU-seitig verwendet, was eine gute Grundlage für schnellere und kürzere Entwurfs-zyklen bietet. Egal wie viele Produktvarianten existieren: Mit der passenden IT-Infrastruktur für OpenFOAM steigern Ingenieure die Qualität von Simulationen und beschleunigen die virtuelle Produktentwicklung signifikant.
Grace Hopper
TM
für
Large Language Models
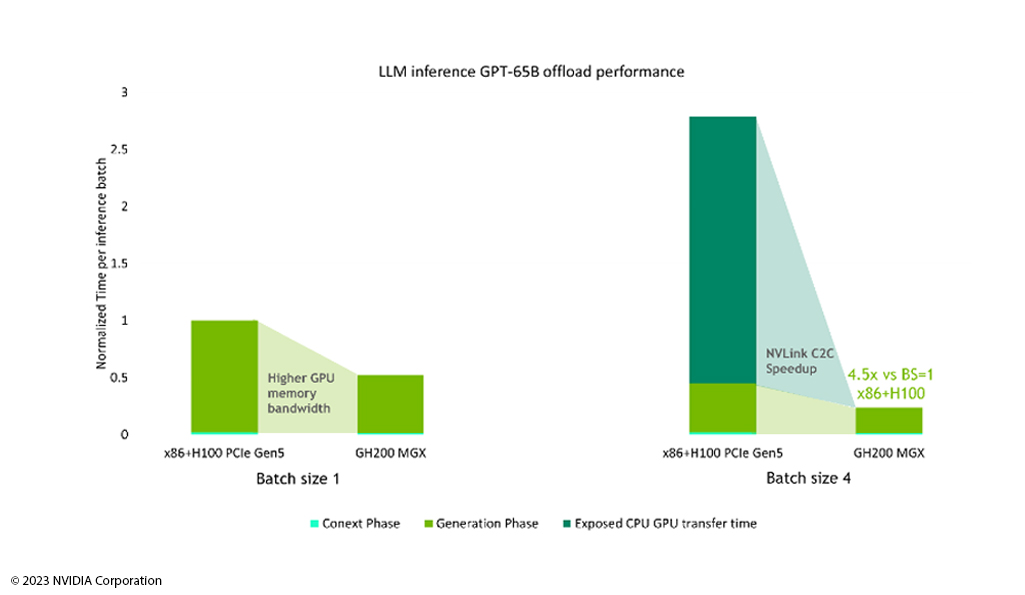
NVIDIA liefert mit Grace Hopper TM einen soliden Server, der optimal zu den Anforderungen anspruchsvoller KI-Workloads skaliert. Large Language-Modelle basieren auf Milliarden bis Billiarden von Daten und benötigen daher eine große Rechenleistung, um das Verstehen und die Erstellung von Sprache zu ermöglichen.
NVIDIA Grace Hopper
TM
ist speziell für das Training großer KI-Modelle entwickelt und ermöglicht durch seine Architektur einen hohen Daten-durchsatz. Aufgrund des verwendeten HBM3-Speicher erreicht Grace Hopper
TM
bei einer Batch Size von 1 eine Speicherbandbreite von nahezu 100 Prozent. Während andere Systeme wie x86 Systeme ab einem Batch Size von 4 einen Leistungsrückgang verzeichnen, unterstützt das NVLink in Grace Hopper
TM
die Workloads um das 4,5 fache. So können trainierte Large Language-Modelle mit Grace Hopper
TM
komplexe Anfragen in kürzester Zeit erfassen und die riesigen Datensätze schnell verarbeiten.
Grace Hopper
TM
für
Rekommender Systems
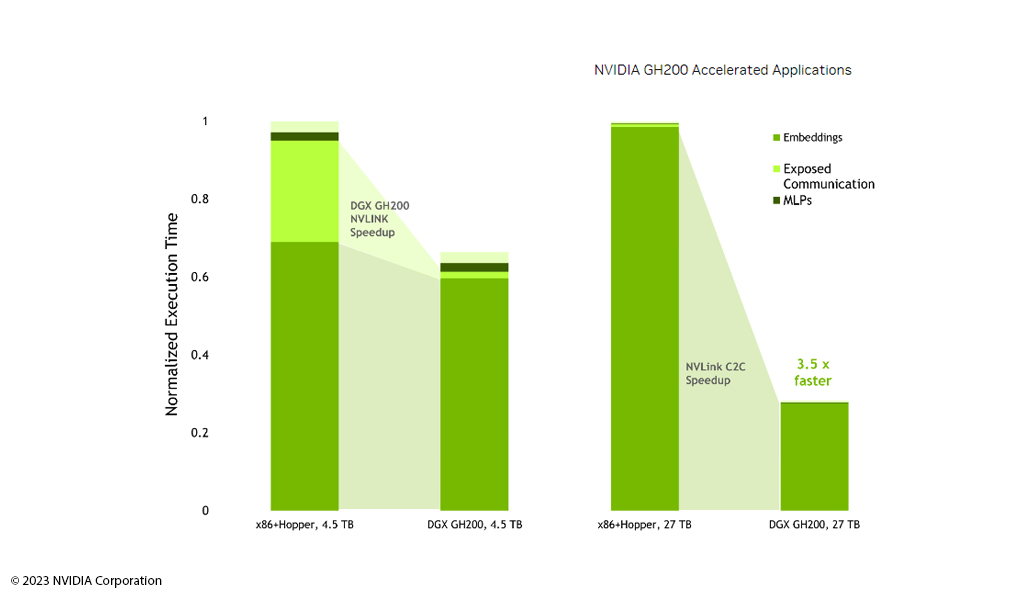
Recommender Systeme (auf Deutsch auch Empfehlungsdienste oder Filter) nutzen leistungsstarke KI-Infrastrukturen, um Endbenutzern und Kunden zu helfen, die Inhalte, Produkte und Dienstleistungen zu finden, an denen sie am meisten interessiert sind. Die dahinterstehende Kombination aus ausgefeilten KI-Modellen und großen Datensätzen erfordert oftmals umfassende Rechenressourcen.
NVIDIA Grace Hopper
TM
ist die richtige Infrastruktur zur Verwaltung großer Modelle und massiver Daten in Empfehlungssystemen und hebt die Interaktion mit nutzergenerierten Inhalten auf eine nächste Stufe. NVIDIA Grace Hopper
TM
fördert hochdurchsatzfähige Empfehlungssystem-Pipelines, da das System eine hervorragende Speicherleistung im CPU-Bereich bietet. Ermöglicht wird dies durch NVIDIAs NVLink: die direkte, leistungsstarke Kommunikationsbrücke zwischen einem Paar GPUs liefert einen High-Bandwidth-Zugriff auf die lokalen HBM3-Speicher und LPDDR5X-Speicher. Dies beschleunigt das Arbeitstempo und unterstützt die verwendeten KI-Modelle dabei präzisere, relevantere und schnellere Ergebnisse an die Endbenutzer zu liefern.
Grace Hopper
TM
für
Graph Neural Networks
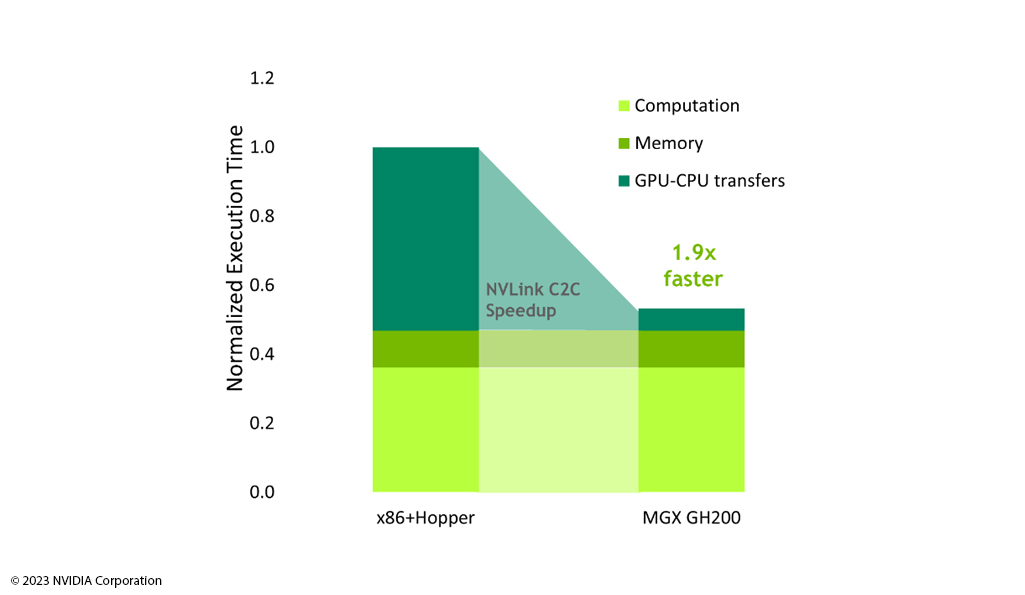
Graph Neural Network (GNN) bietet bereits heute beeindruckende Leistung und eine hohe Interpretierbarkeit, insbesondere in dem Bereich, in dem Beziehung und Interaktion von Daten eine wichtige Rolle spielen. Damit die Modelle in kurzer Zeit große Datenmengen genaue analysieren und vorhersagen können, bedarf es einer hohen Rechenleistung.
NVIDIA Grace Hopper
TM
bietet für Anwendungsfälle im Bereich von GNN die richtige Infrastruktur. Anwender erhalten mit Grace Hopper
TM
die strukturelle Basis, um schnell und effizient die numerische Darstellung eines Graphen zu konstruieren, die später zum Trainieren von Machine-Learning-Algorithmen verwendet werden kann. Für die Verarbeitung strukturierter Daten und das Training von GNN steht dem Anwender ein hoher Bandbreitenzugriff auf LPDDR5X und eine NVLink-C2C-Verbindung zur Verfügung. Die großen Speicherkapazitäten von Grace Hopper
TM
lösen graphenbasierte, maschinelle Lernaufgaben in kürzester Zeit.
Sie möchten mehr erfahren?
Weitere Informationen finden Sie im NVIDIA-Whitepaper
'Performance and Productivity for Strong-Scaling HPC and Giant AI Workloads'
Unsere Partner für Ihren Erfolg
Gemeinsam mit unseren langjährigen Partnern beraten wir Sie ganzheitlich sowie detailtief und sorgen für eine praxisbewährte Umsetzung ihrer KI-Infrastrukturen.

Unsere Services

Machine Learning & AI

Smarte AI-Algorithmen als Bestandteil
Ihrer Digitalisierungsstrategie

Managed Service HPC

Wir übernehmen Ihren IT-Betrieb teilweise oder ganz - für mehr Zufriedenheit Ihrer Experten bei der Projektabwicklung.
Hybrid HPC

Die Vorzüge von vor Ort gehosteten Infrastrukturen mit den Vorteilen der Cloud vereinen und das Optimum aus HPC-Workflows herausholen.
Cloud HPC

Mit HPC in der Cloud komplexe Probleme lösen und mehr Flexibilität für simulationsintensive Workloads erreichen.
CAE-Automation

Ziehen Sie den größtmöglichen Nutzen
aus Ihren Simulationsdaten - mit automatisierten und standardisierten Workflows.
CAE-Lösungen

Praxisorientierte Zusatztools für alle Anforderungen, die CAD-Systeme 'von der Stange' nicht abdecken.
Engineering Workplace

Die virtuelle Arbeitsumgebung mit leistungsstarker Rechenpower und
State-of-the-Art-Technologien für
alle HPC-Aufgaben.
