
The demand for artificial intelligence (AI) is constantly increasing and with it the need for computing capacity. AI applications such as deep learning, simulations or forecasts require extremely powerful hardware in order to generate valid results from complex data sets. Server systems with NVIDIA's Grace Hopper TM chip perfectly meet these requirements today and in the future: the superchip was specially developed for training large AI models, generative AI, recommender systems and data analysis.
Click Here for 1st Hand Superchip Knowledge
AI today - Ready for Take-off
The progress of smart AI technologies has increased rapidly in the past few years: AI applications such as chat GPT, simulations in domains such as medicine or recommender systems in online stores solve complex tasks and make our everyday lives easier. More intelligent algorithms and more complex data analyses are multiplying the possible applications. However, AI-driven progress requires computing power - and ever more of it. System architectures such as NVIDIA's Grace Hopper TM provide the necessary power for rapidly developing AI technologies.
- Powerful: Grace Hopper's TM combination of GPU, CPU and NVLink interconnect offers maximum performance across many benchmarks.
- Versatile: There are already many applications running on Grace Hopper TM, and the number is growing.
- Energy-saving: NVIDIA Grace Hopper TM requires less energy compared to x86 systems.
Best Practices for Your Success
Server systems with NVIDIA Grace Hopper
TM
Superchip:
The first choice for your CEA workloads
-
Learn more about the most powerful architecture on the market today to help you
quickly master large-scale AI calculations and complex CAE simulations.
- Introducing Grace Hopper:
Get to know the powerful architecture of the NVIDIA Hopper GPU with the Grace CPU
(ARM Architecture) and the fast NVLink Chip-2-Chip (C2C). - Optimized Performance:
NVIDIAs Grace Hopper TM delivers tremendous performance to process large CAE/CFD workloads
in the shortest possible time. - Benchmark Insights:
Grace Hopper TM is particularly powerful with the CFD software OpenFOAM.
Find out more details using selected benchmarks. - Order Now and Starting with Computing Power for AI:
NVIDIA Grace Hopper TM Superchip is available directly from GNS Systems.
Your Individual Consultation for
5 x Higher Performance
Do you have any questions? Then get in touch with us. Our experts will be happy to advise you on all aspects of Grace Hopper TM and powerful server systems for efficient AI use.
Best Performance for AI
large data sets, for example in deep learning algorithms. The NVIDIA Grace Hopper TM systems are currently among the most powerful architectures on the market.
The new combination of NVIDIA Hopper GPU with the Grace CPU (ARM architecture) and the fast NVLink Chip-2-Chip (C2C) offers up to five times
higher performance for applications than comparable x86 systems.
Architecture Features
Grace Hopper TM combines the powerful NVIDIA Hopper GPU with the Grace CPU (ARM Architecture) and connects it with the fast NVLink Chip-2-Chip (C2C).
The first NVIDIA data center CPU for HPC and AI workloads, the NVIDIA Grace CPU uses 72 Arm Neoverse V2 CPU cores to get the maximum per-thread performance out of the system. Up to 480 GB LPDDR5X memory provides the optimal balance between memory capacity, energy efficiency and performance.
NVIDIA Hopper is the ninth generation of the NVIDIA Data Center GPU and is specifically designed for large-scale AI and HPC applications. The thread block clusters and thread block reconfiguration used improve spatial and temporal data locality and keep the units in use utilized.
NVIDIA NVLink-C2C is NVIDIA's memory coherent and low latency interconnect standard for superchips. It forms the heart of the Grace Hopper TM superchip and delivers a total bandwidth of up to 900 GB/s.
|
Processor
|
Processor Family: NVIDIA Grace Hopper TM Superchip Processor Type: NVIDIA Grace TM 72 Arm® Neoverse V2 cores Max. TDP Support: 1000W Number of Processors: (1) Processors Internal Interconnect: NVIDIA® NV-Link®-C2C 900GB/s |
|
Core architecture
|
2U Rackmount |
| Cache | W x H x D (inch): 17.24" x 3.44" x 35.43" W x H x D (inch): 438 x 87.5 x 900mm |
|
Storage
|
Default Configuration: (4) E1.S NVMe SSD
|
|
Memory size
|
Capacity: Up to 480GB LPDDRX embedded 96GB HBM3 GPU memory
|
|
Expansion Slot
|
Default Configuration: (3) PCle 5.0 x16 FHFL Dual Width slots
|
|
Front I/O
|
Power / ID / Reset Button Power / ID / Status LEDs (2) USB 3.0 ports (1) VGA port |
|
Storage Controller
|
Broadcom HBA 9500 Series Storage Adaptor Broadcom MegaRAID 9560 Series |
| Power |
1+1 High efficiency hot-plug 2000W PSU, 80 Plus Titanium |
Whether deep learning, NLP (Natural Language Processing) or data analysis - NVIDIA's Grace Hopper TM delivers enormous performance to enable extensive AI calculations and simulations of complex relationships in the shortest possible time.
High Speed
for Your Innovations
Grace HopperTM
for
OpenFOAM
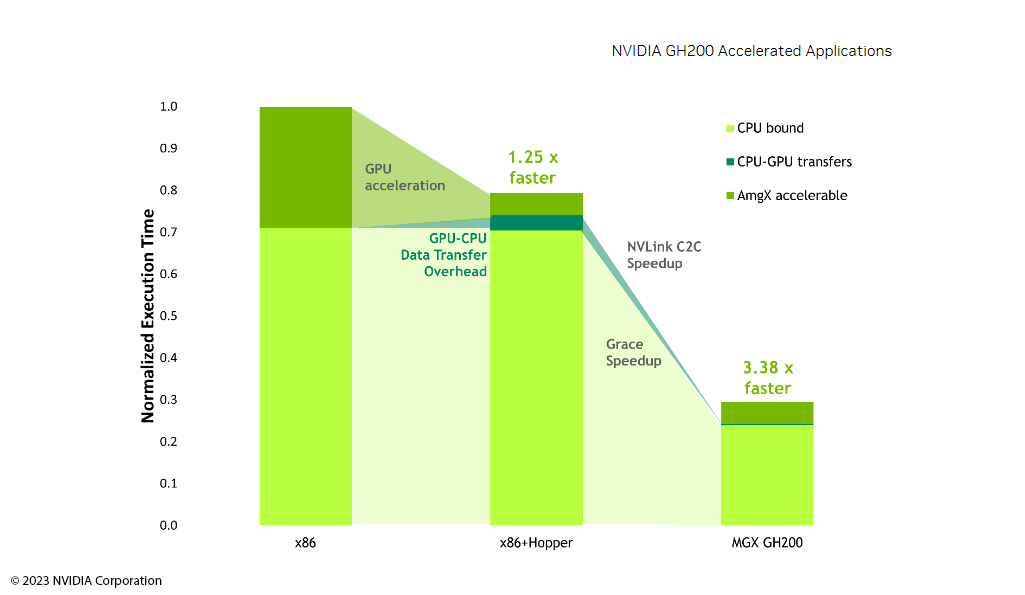
The NVIDIA Grace Hopper TM provides developers with a modular system that optimally supports even demanding CFD simulations with OpenFOAM. For the application of complex simulation models in product development, it is necessary to carry out the calculations in massive parallel on the latest computing architectures.
OpenFOAM-based applications on Grace Hopper TM architectures make optimum use of the performance potential of the servers. Compared to other systems such as the x86 system without Hopper, the NVIDIA Grace Hopper TM architecture only requires 15 percent instead of 35 percent runtime. As a rule, only 85 percent of the runtime is used on the CPU side, which provides a good basis for faster and shorter design cycles. No matter how many product variants exist: With the right IT infrastructure for OpenFOAM, engineers increase the quality of simulations and significantly accelerate virtual product development.
Grace HopperTM
for
Large Language Models
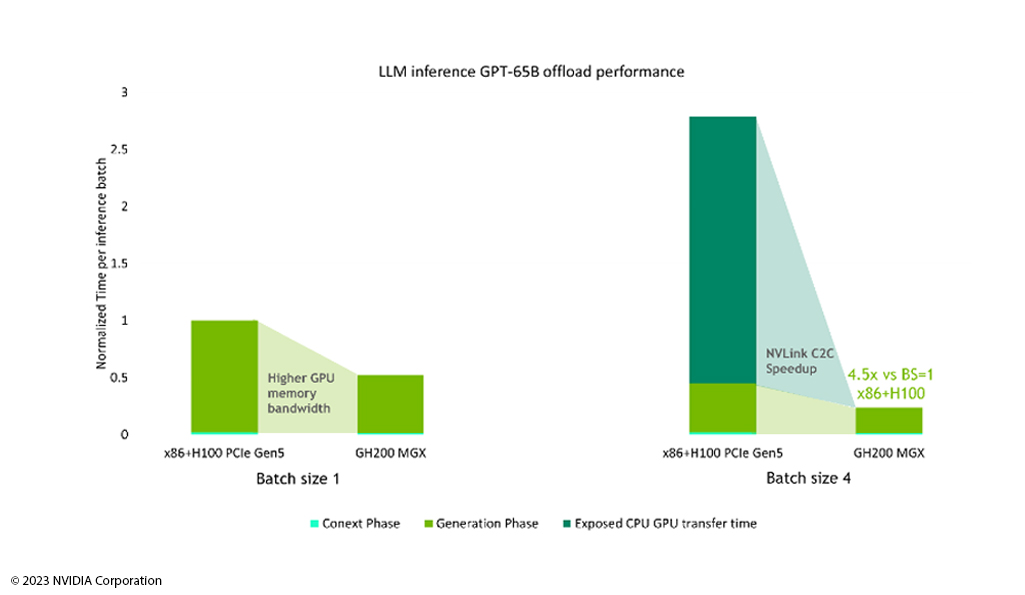
With Grace Hopper TM, NVIDIA delivers a solid server that scales optimally to the requirements of demanding AI workloads. Large language models are based on billions to quadrillions of pieces of data and therefore require large computing power to enable language understanding and creation.
NVIDIA Grace Hopper TM is specially developed for training large AI models and enables high data throughput thanks to its architecture. Due to the HBM3 memory used, Grace Hopper TM achieves a memory bandwidth of almost 100 percent with a batch size of 1. While other systems such as x86 systems experience a drop in performance from a batch size of 4, the NVLink in Grace Hopper TM supports workloads by a factor of 4.5. This means that trained large language models with Grace Hopper TM can capture complex queries in the shortest possible time and process the huge data sets quickly.
Grace HopperTM
for
Rekommender Systems
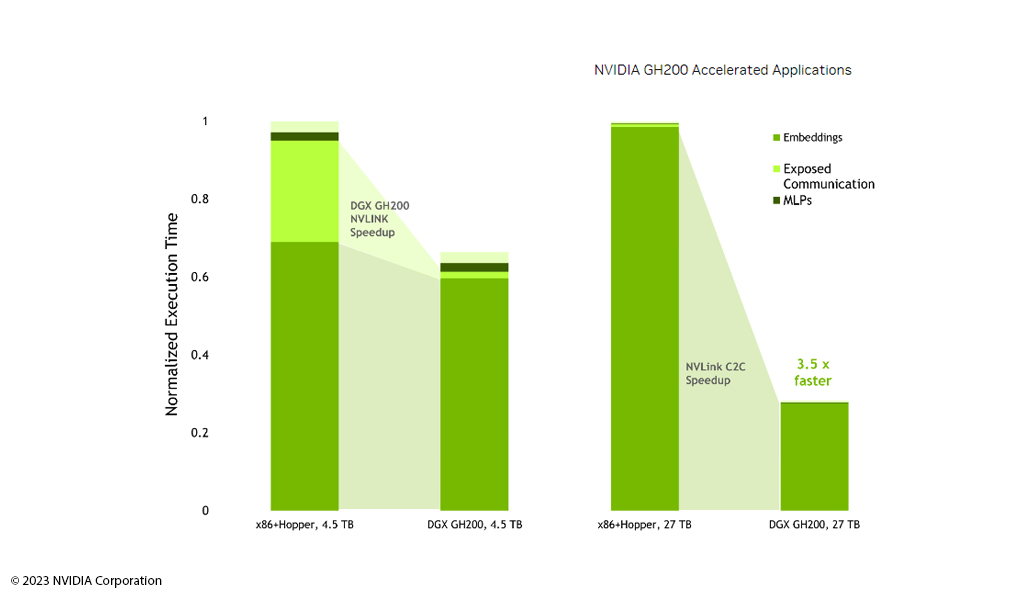
Recommender systems (also known as recommendation services or filters) use powerful AI infrastructures to help end users and customers find the content, products and services they are most interested in. The underlying combination of sophisticated AI models and large data sets often requires extensive computing resources.
NVIDIA Grace Hopper TM is the right infrastructure to manage large models and massive data in recommender systems and takes interaction with user-generated content to the next level. NVIDIA Grace Hopper TM drives high-throughput recommender system pipelines by delivering outstanding CPU memory performance. This is made possible by NVIDIA's NVLink: the direct, high-performance communication bridge between a pair of GPUs delivers high-bandwidth access to HBM3 local memory and LPDDR5X memory. This accelerates the speed of work and helps the AI models used to deliver more accurate, relevant and faster results to end users.
Grace HopperTM
for
Graph Neural Networks
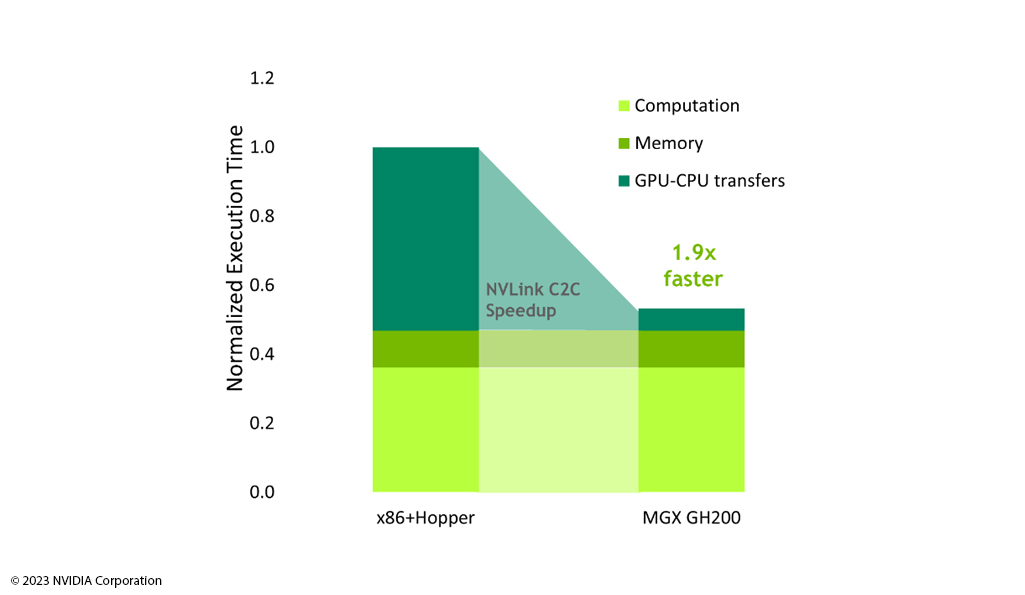
Graph Neural Network (GNN) already offers impressive performance and high interpretability, especially in the area where relationship and interaction of data play an important role. However, high computing power is required to enable the models to accurately analyze and predict large amounts of data in a short period of time.
NVIDIA Grace Hopper TM offers the right infrastructure for use cases in the field of GNN. Grace Hopper TM provides users with the structural basis to quickly and efficiently construct the numerical representation of a graph, which can later be used to train machine learning algorithms. For the processing of structured data and the training of GNN, the user has high bandwidth access to LPDDR5X and an NVLink C2C connection. The large memory capacities of Grace Hopper TM solve graph-based machine learning tasks in the shortest possible time.
Would you like to learn more?
You will find further information in the NVIDIA-Whitepaper
'Performance and Productivity for Strong-Scaling HPC and Giant AI Workloads'
Our competencies for your projects
Together with our long-standing partners, we provide you with holistic and detailed advice and ensure that your AI infrastructures are implemented in a practice-proven manner.

Our services



Managed Service HPC

We can take over your IT operations in part or in full - for greater satisfaction of your experts in project management.
Hybrid HPC

Solve complex problems and achieve greater flexibility for simulation-intensive workloads with HPC in the cloud.
Cloud HPC

Solve complex problems and achieve greater flexibility for simulation-intensive workloads with HPC in the cloud.
CAE Automation

Get the most out of your simulation data - with automated and standardized workflows
CAE Solutions

Practice-oriented additional tools for all requirements that are not covered by
'off-the-peg' CAD systems.
Engineering Workplace

The virtual work environment with powerful computing power and state-of-the-art technologies for all HPC tasks.
